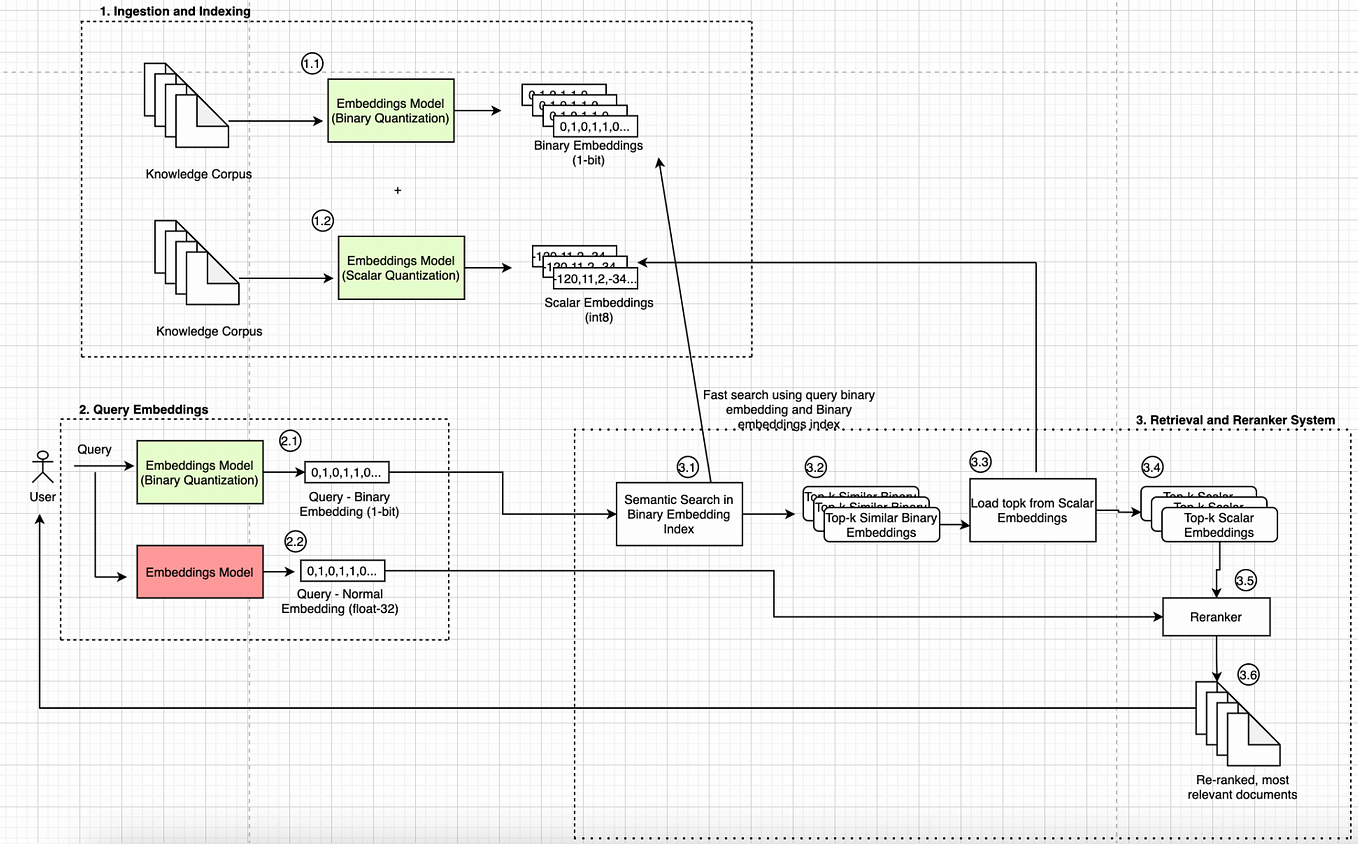
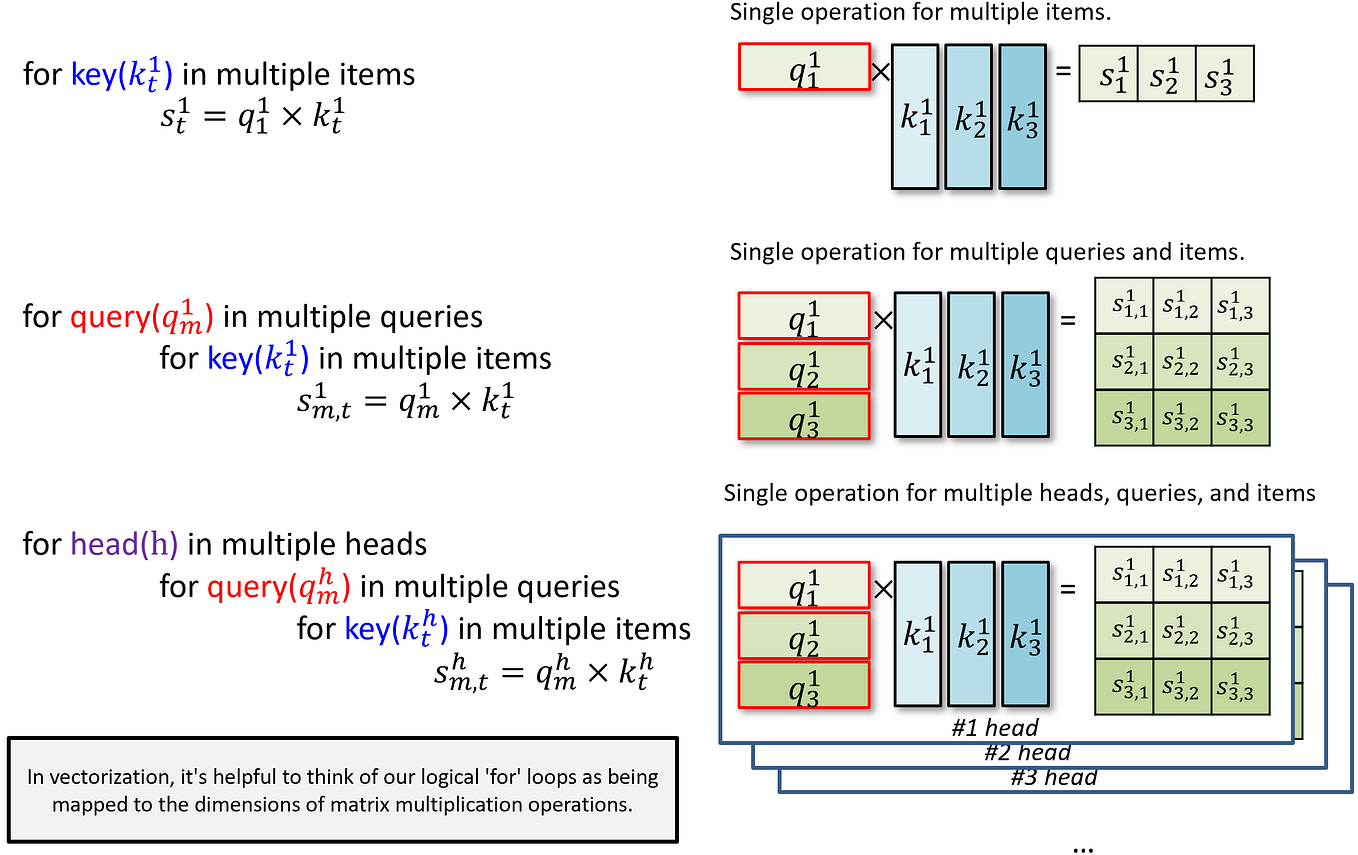
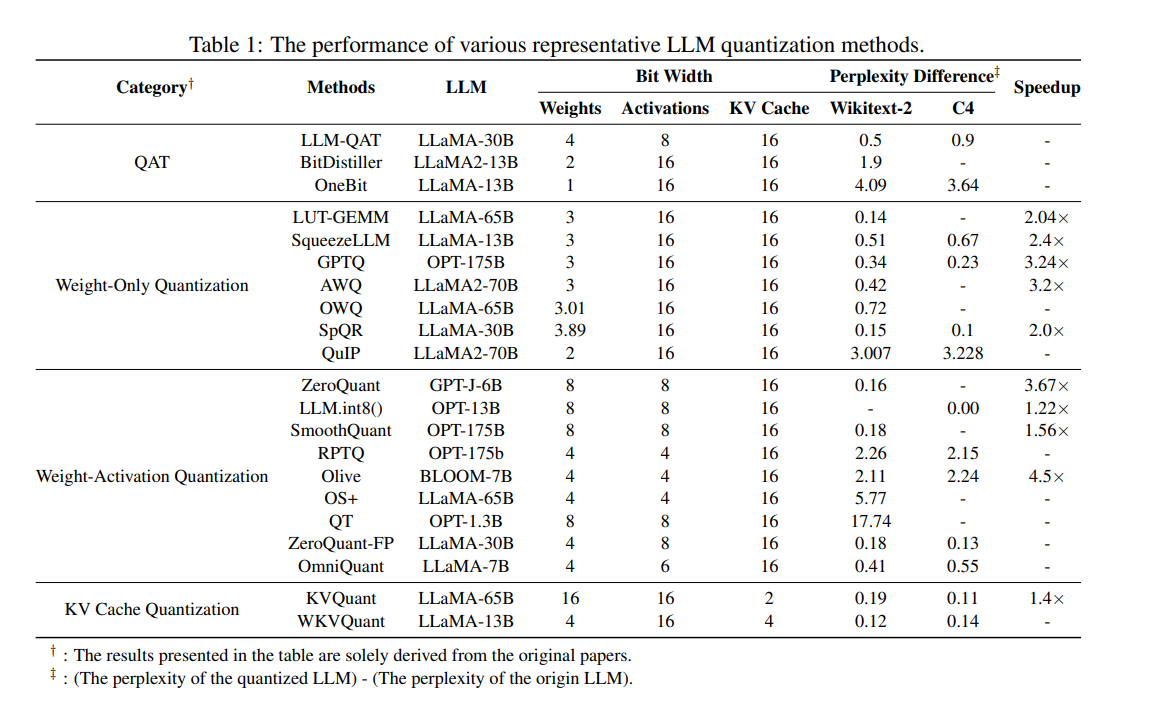
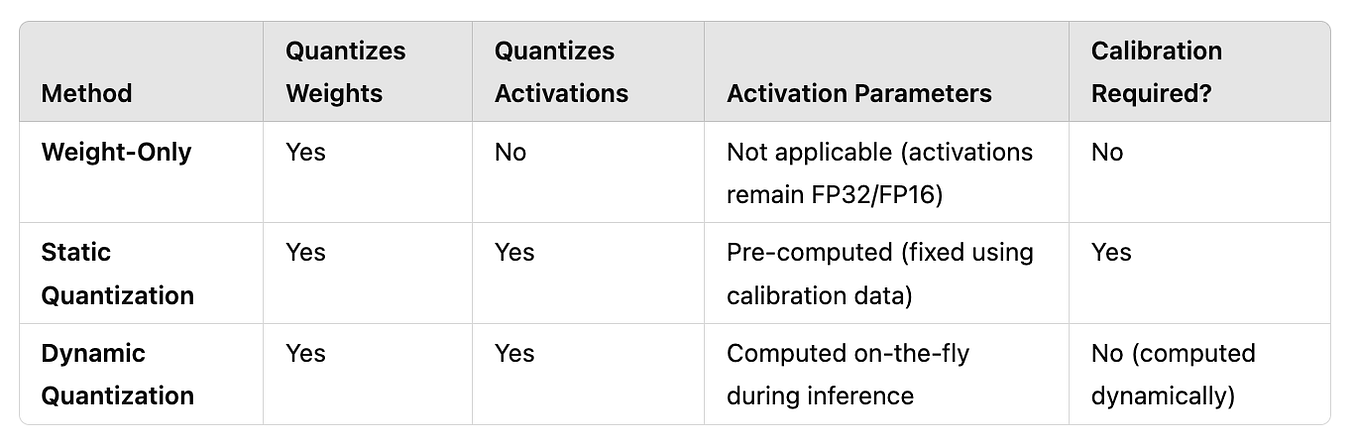
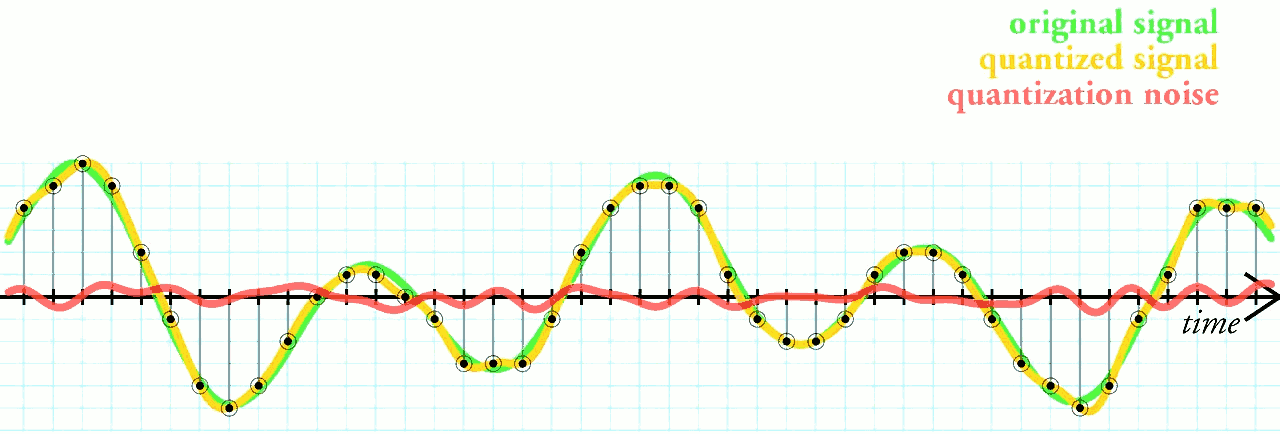
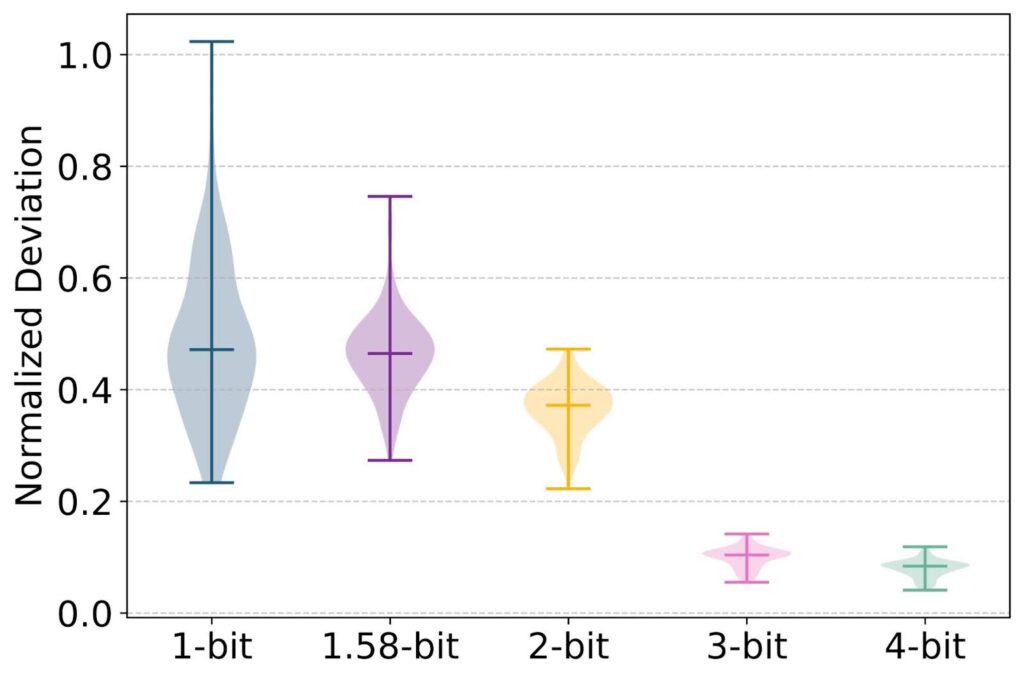
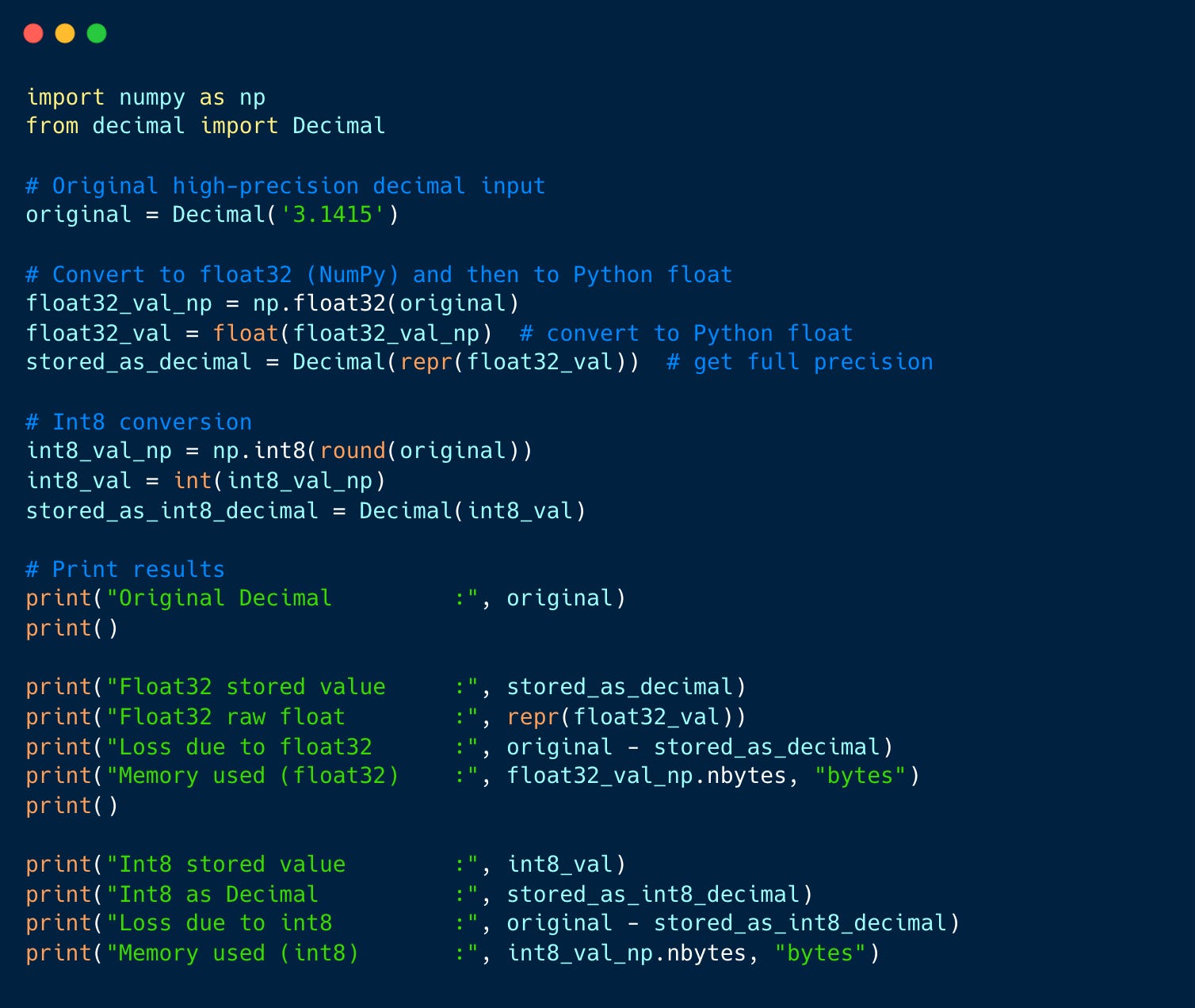
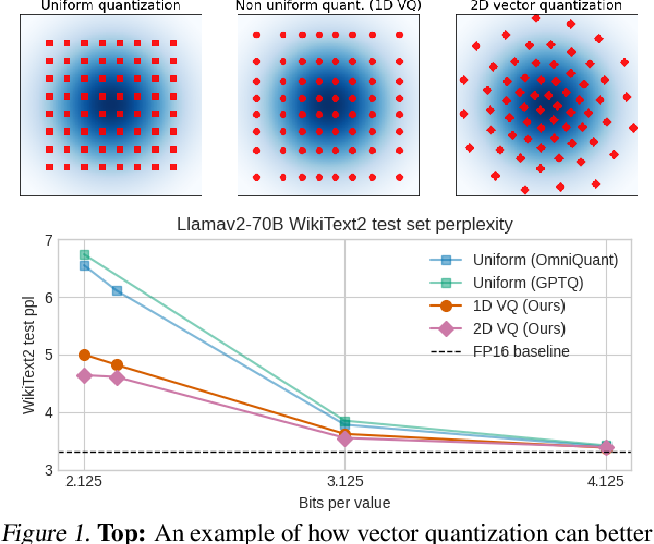
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
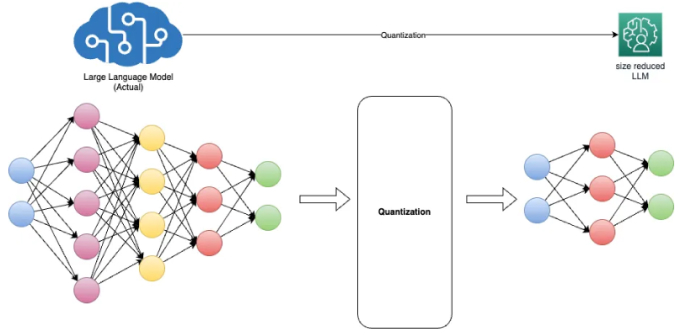
Optimizing LLM Model using Quantization
Understanding LLM Quantization. With the surge in applications using ...
LLM Inference with Codebook-based Q4X Quantization using the Llama.cpp ...
LLM Quantization-Build and Optimize AI Models Efficiently
The Ultimate Handbook for LLM Quantization | Towards Data Science
Improving LLM Inference Latency on CPUs with Model Quantization ...
4-bit LLM training and Primer on Precision, data types & Quantization
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
LLM Quantization with Hugging Face Transformers
Top LLM Quantization Methods and Their Impact on Model Quality
Overview of LLM Quantization Techniques & Where to Learn Each of Them ...
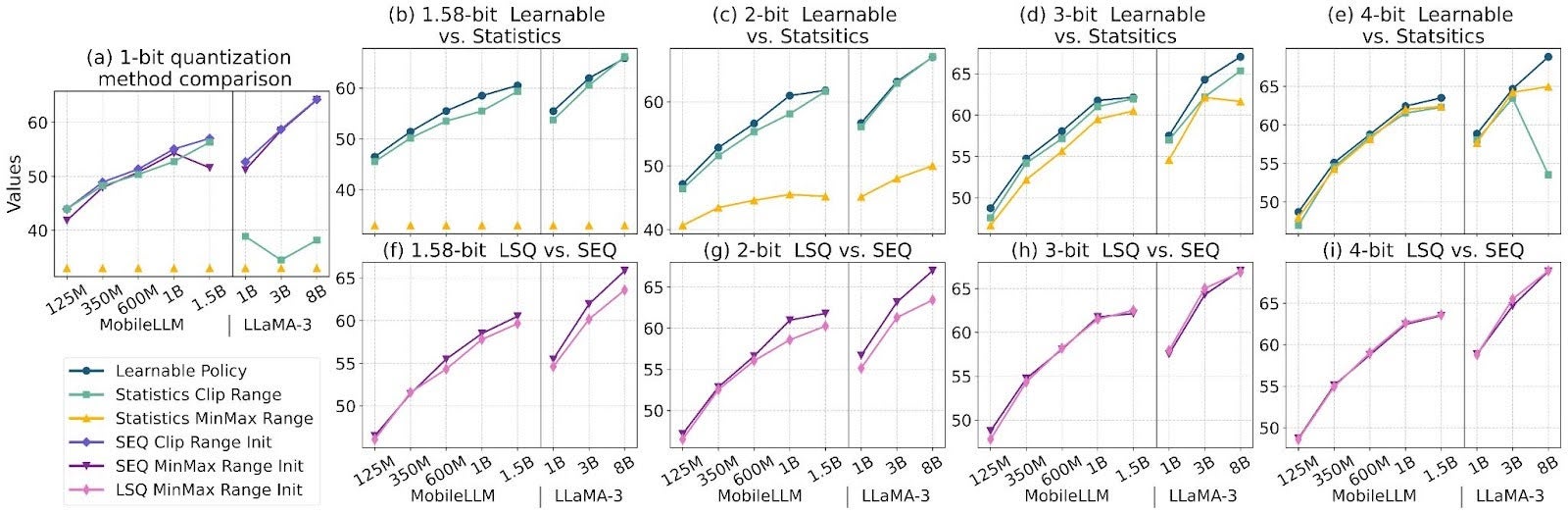
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
Practical Guide to LLM Quantization Methods - Cast AI
5 Essential LLM Quantization Techniques Explained
A Comprehensive Guide on LLM Quantization and Use Cases
LLM Quantization Made Easy: Essential Tips for Success
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable ...
(PDF) Exploiting LLM Quantization
Quantizing Models with Activation-Aware Quantization (AWQ) - LLM ...
LLM By Examples — Use GGUF Quantization | by MB20261 | Medium
What is LLM Quantization and How to Use Them?
A Visual Guide to LLM Quantization - Bens Bites
LLM Model Quantization: An Overview - | Comidoc
A Beginner's Guide to LLM Quantization
LLM Quantization: An Introduction to Quantization Techniques
What is LLM Quantization? How Does It Work & Types
LLM Quantization Explained - YouTube
SpinQuant: LLM Quantization with Learned Rotations
Paper page - SpinQuant: LLM quantization with learned rotations
Toward Efficient LLM Inference: A Quantitative Evaluation of ...
LLM Tutorial 21 — Model Compression Techniques: Quantization, Pruning ...
LLM By Examples — Use GPTQ Quantization | by MB20261 | Medium
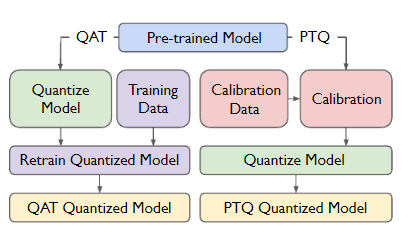
LLM Quantization Aware Training | PDF | Applied Mathematics | Machine ...
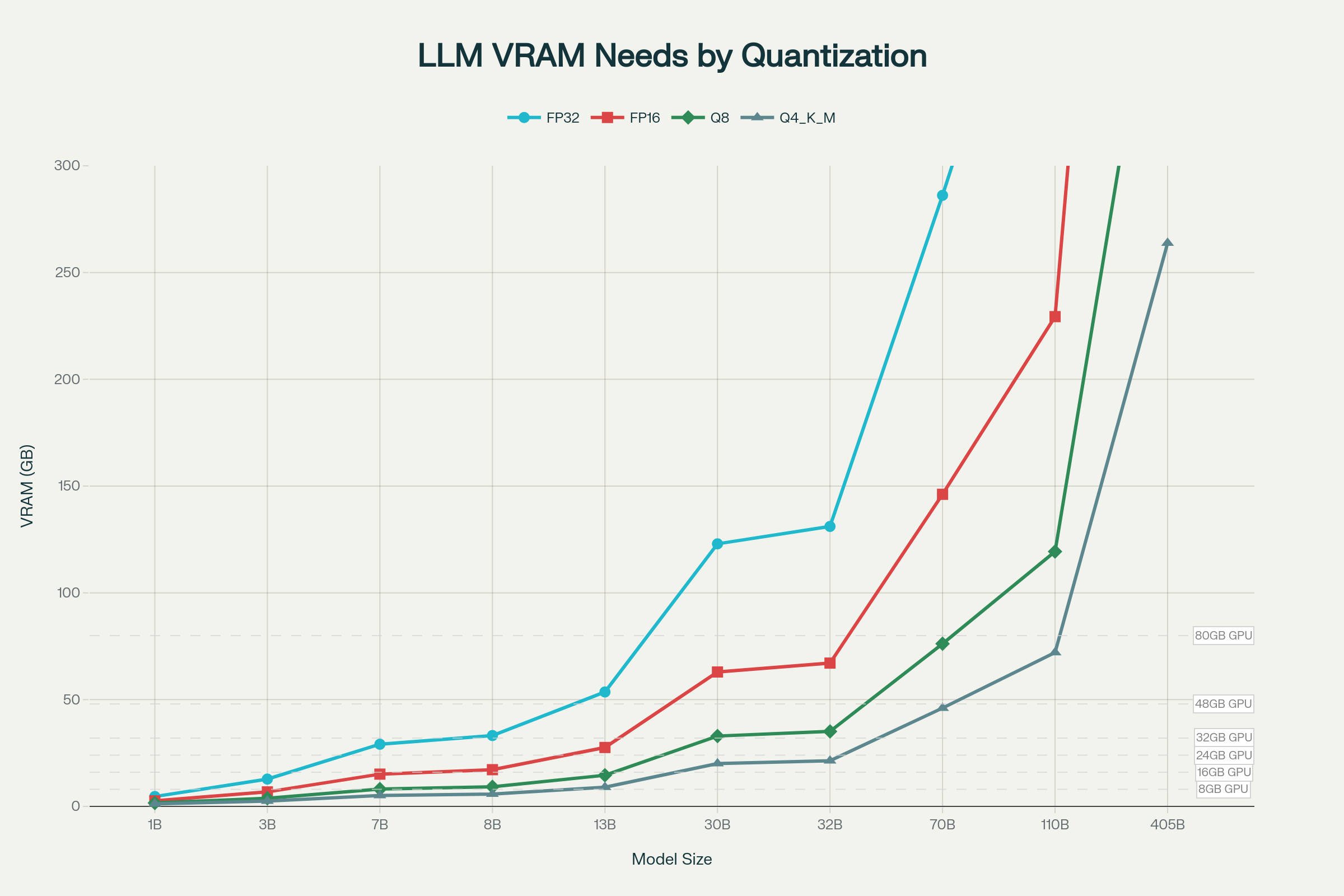
The Best GPUs for Local LLM Inference in 2025 | LocalLLM.in
How to compute LLM embeddings 3X faster with model quantization | by ...
Quantization Techniques to Reduce LLM Model Size and Memory: A Complete ...
LLM Quantization: Making models faster and smaller | MatterAI Blog
Improving LLM Inference Speeds on CPUs with Model Quantization | by ...
The Newbie’s Handbook on LLM Quantization and Model Compression | by ...
What is Quantization? - LLM Concepts ( EP - 3 ) #quantization #llm #ml ...
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
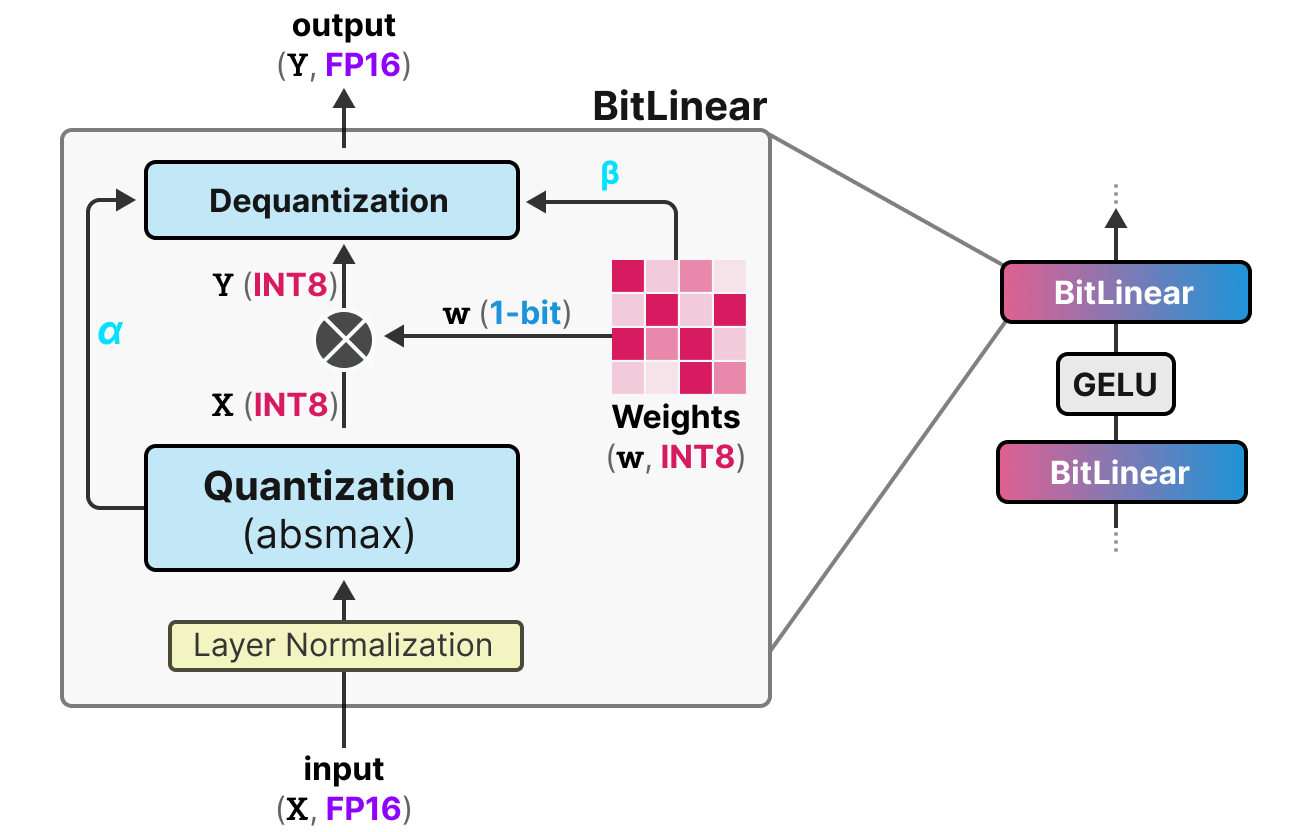
1-Bit LLM and the 1.58 Bit LLM- The Magic of Model Quantization | by Dr ...
How to optimize large deep learning models using quantization
ローカル実行の常識! LLM 量子化 ( Quantization ) の仕組みと手法を完全理解する #軽量化 - Qiita
LLM Compression Techniques to Build Faster and Cheaper LLMs
LLM inference optimization: Model Quantization and Distillation - YouTube
New Method For LLM Quantization | ml-news – Weights & Biases
QUAD: Quantization and Parameter-Efficient Tuning of LLM with ...
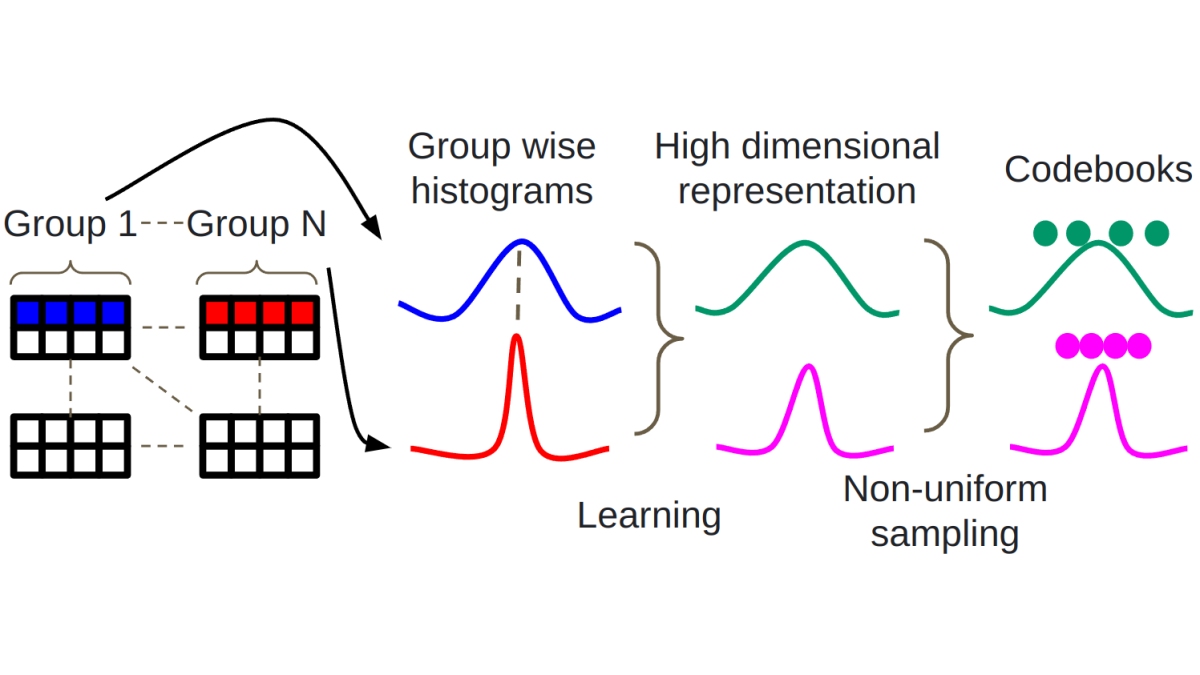
GPTVQ: The Blessing of Dimensionality for LLM Quantization
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
vLLM: A Deep Dive into Efficient LLM Inference and Serving | by ...
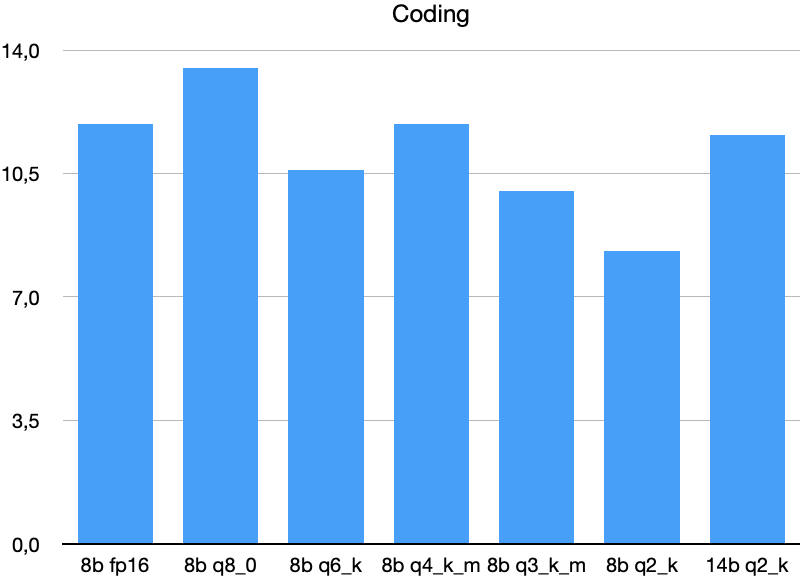
LLM Quantization Comparison
LLM Quantization Explained in simple language: How to Reduce Memory ...
[Research Paper Summary]Exploiting LLM Quantization | by Himanshu ...
LLM by Examples — Use GGML Quantization | by MB20261 | Medium
Oaken: Fast and Efficient LLM Serving with Online-Offline Hybrid KV ...
8 local LLM settings most people never touch that fixed my worst AI ...
A Coding Tutorial for Running PrismML Bonsai 1-Bit LLM on CUDA with ...
Local LLM Runtime Comparison
Monsoon's Blog
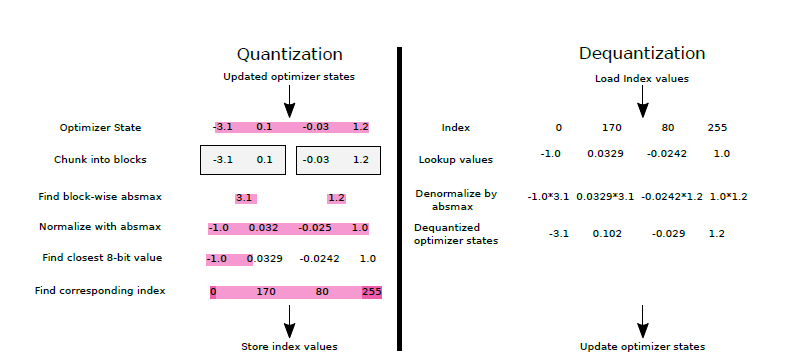
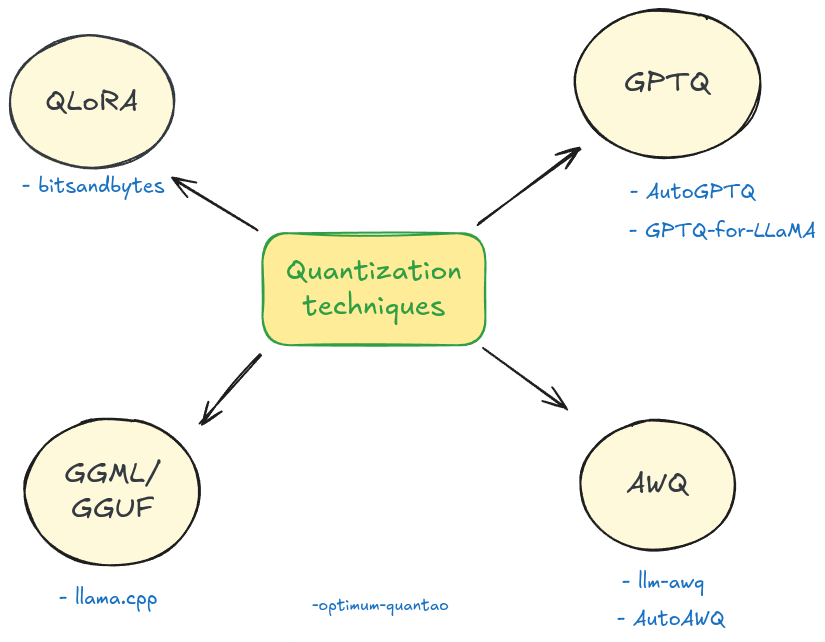
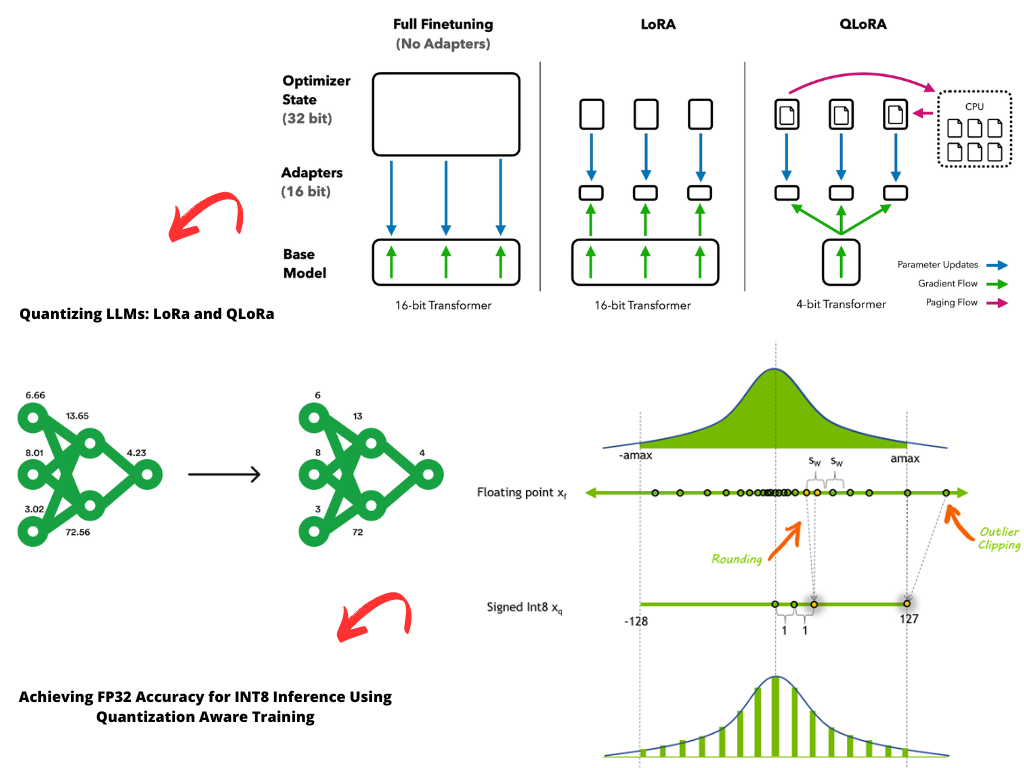
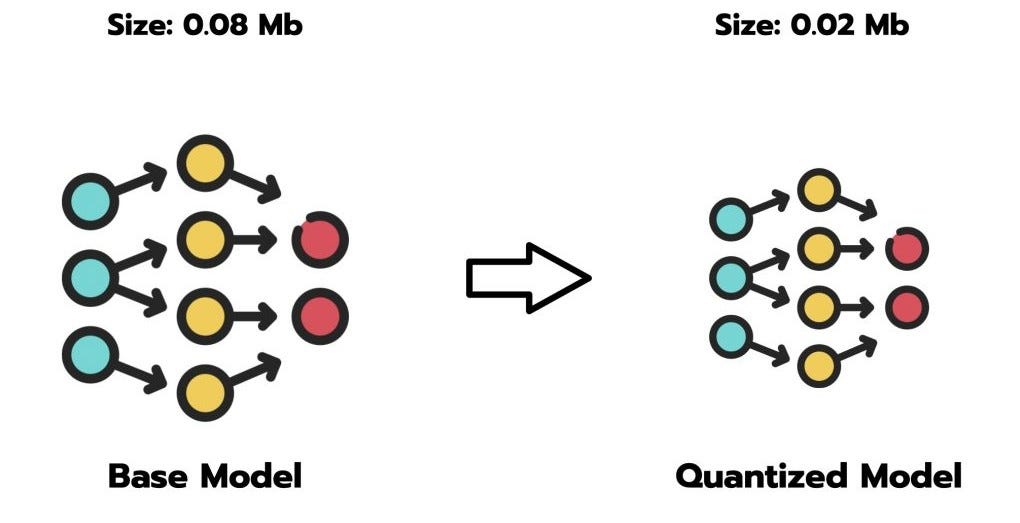
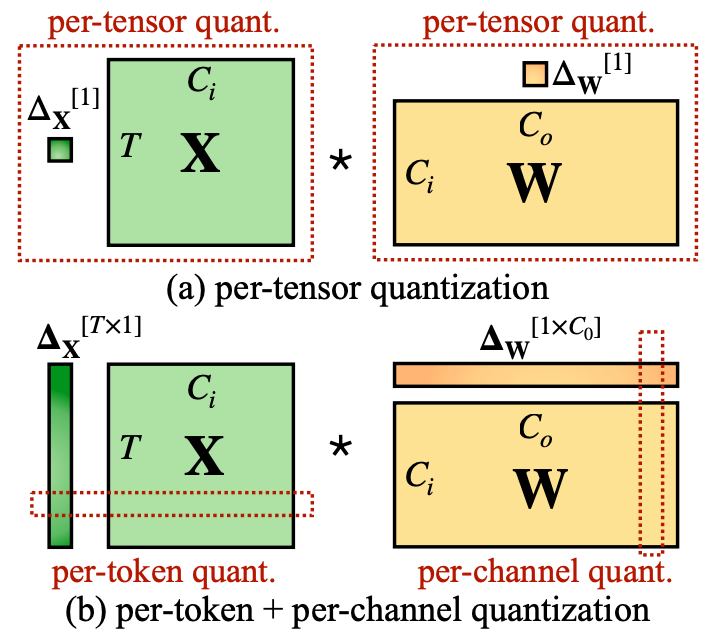
A Visual Guide to Quantization - by Maarten Grootendorst
What is Quantization in LLM? A Complete Guide to Optimizing AI
Maximizing Business Potential with Large Language Models (LLMs)
LLM-QAT: Data-Free Quantization Aware Training for Large Language ...
模型量化-llm量化 - 知乎
4-bit Quantization with GPTQ | Towards Data Science
Making LLMs lighter with AutoGPTQ and transformers
How to run LLMs on CPU-based systems | UnfoldAI
Why New LLMs use an MoE Architecture | Exxact Blog
Norma | AI & Data Engineering Company
What is Quantization in LLM. Large Language Models comes in all… | by ...
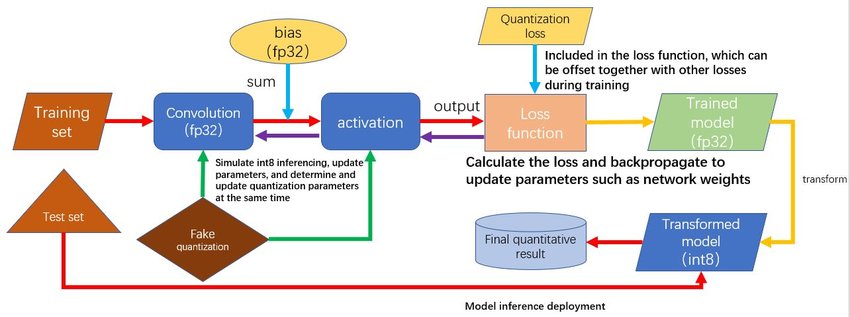
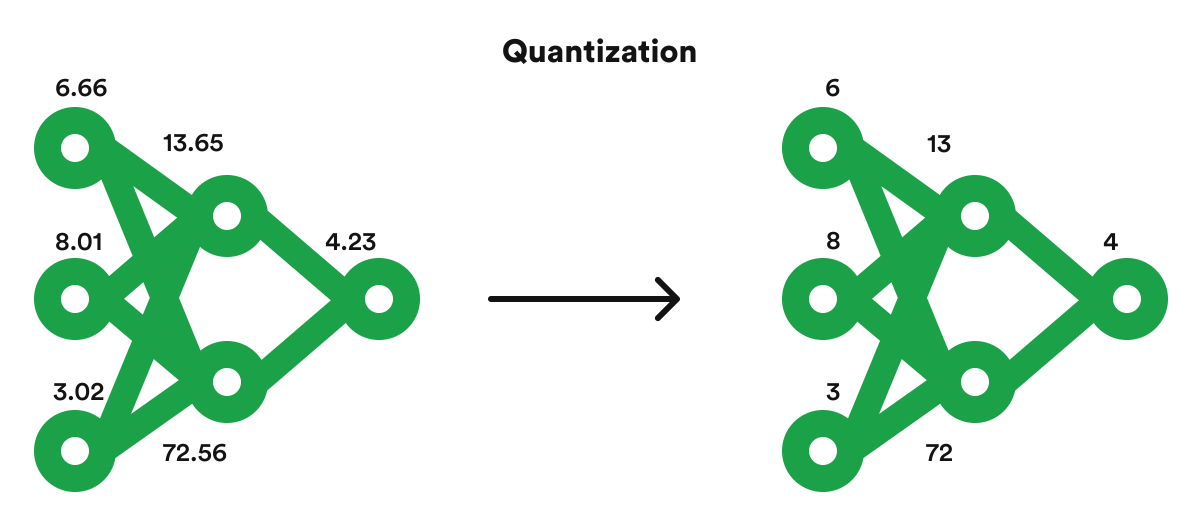
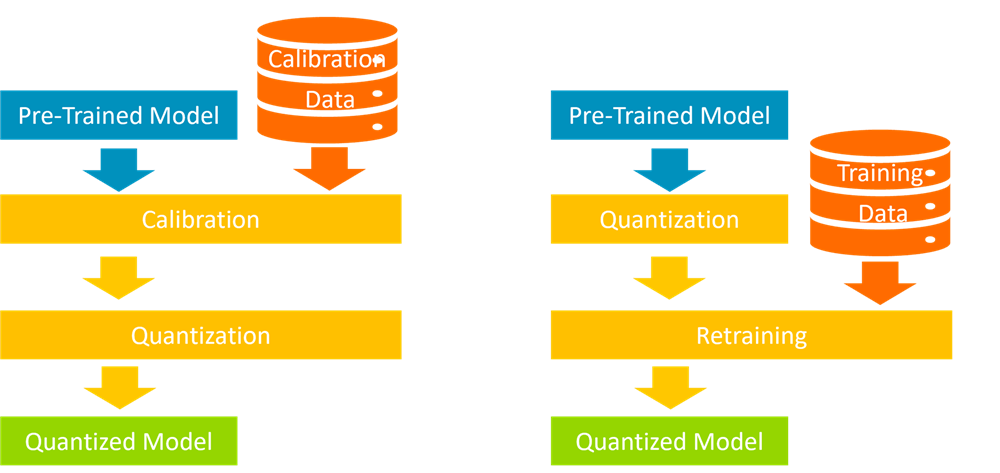
Quantization Process Block Diagram Explained
Exploring Model Quantization for LLMs | by Snehal | Medium
Paper page - LLM-QAT: Data-Free Quantization Aware Training for Large ...
A Guide to Quantization in LLMs | Symbl.ai
TensorRT-LLM-Quantization/quant.ipynb at main · CactusQ/TensorRT-LLM ...
Understanding Quantization for LLMs | by LM Po | Medium
Quantization explained in simple terms for working IT professionals
Neural Network Model quantization on Mobile - AI and ML blog - Arm ...
A Visual Guide to Quantization - Maarten Grootendorst
Fine-tuning-LLM-models-MISTRA-AI-and-OenAI-optimisation-using ...